1. InnoDB 表结构
从物理意义上来讲,InnoDB 表由共享表空间、日志文件组(redo文件组)、表结构定义文件组成。
若将innodb_file_per_table设置为on,则系统将为每一个表单独的生成一个table_name.ibd的文件,在此文件中,存储与该表相关的数据、索引、表的内部数据字典信息。表结构文件则以.frm结尾,这与存储引擎无关。
创建 account 表:
CREATE TABLE `account` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`balance` int(6) NOT NULL,
`firstname` char(10) NOT NULL,
`lastname` char(10) NOT NULL,
`age` int(3) DEFAULT NULL,
`gender` char(2) DEFAULT NULL,
`address` char(30) DEFAULT NULL,
`city` char(10) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
查看数据存储目录:
ls
account.frm account.ibd db.opt
1.1. InnoDB 逻辑存储结构
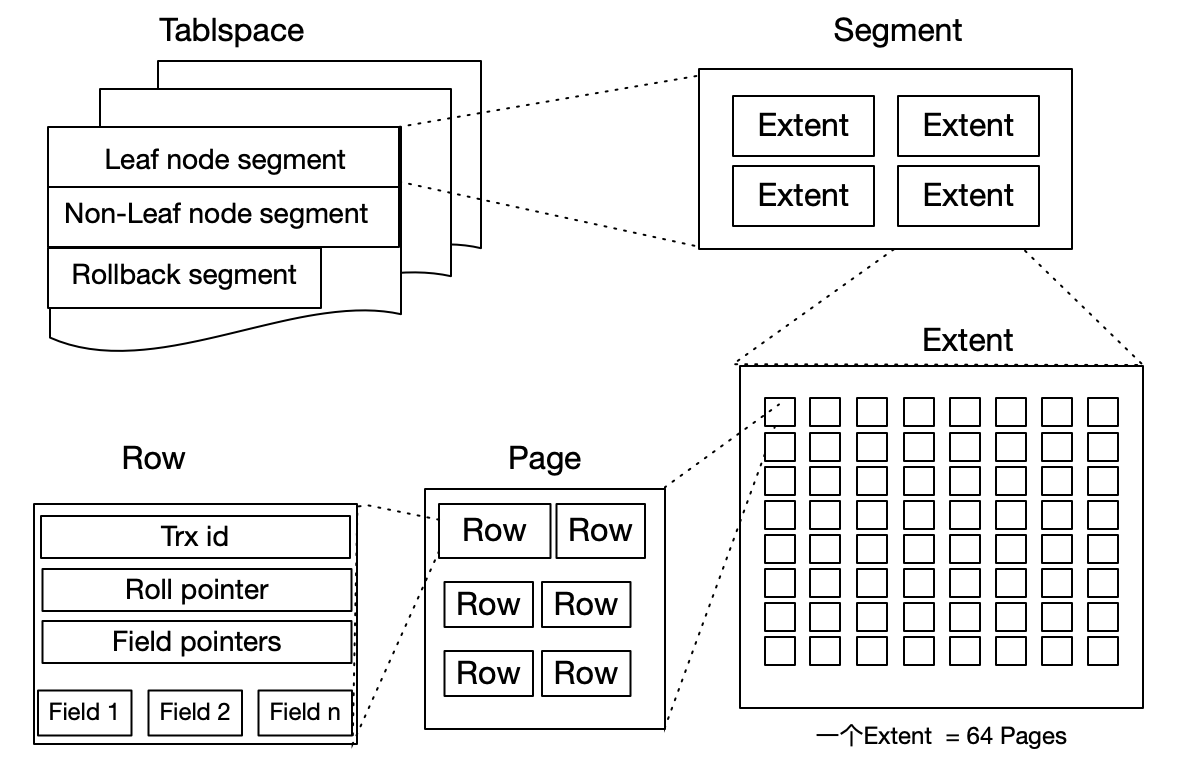
MySQL表中的所有数据被存储在一个空间内,称之为表空间,表空间内部又可以分为段(segment)、区(extent)、页(page)、行(row),逻辑结构如下图:
-
段(segment)
表空间是由不同的段组成的,常见的段有:数据段,索引段,回滚段等等,在 MySQL中,数据是按照
B+tree来存储,因此数据即索引,因此数据段即为B+tree的叶子节点,索引段为B+tree的非叶子节点,回滚段用于存储undo日志,用于事务失败后数据回滚以及在事务未提交之前通过undo日志获取之前版本的数据,在InnoDB1.1版本之前一个InnoDB,只支持一个回滚段,支持1023个并发修改事务同时进行,在InnoDB1.2版本,将回滚段数量提高到了128个,也就是说可以同时进行128*1023个并发修改事务。 -
区(extent)
区是由连续页组成的空间,每个区的固定大小为1MB,为保证区中页的连续性,InnoDB会一次从磁盘中申请4~5个区,在默认不压缩的情况下,一个区可以容纳64个连续的页。但是在开始新建表的时候,空表的默认大小为96KB,是由于为了高效的利用磁盘空间,在开始插入数据时表会先利用32个页大小的碎片页来存储数据,当这些碎片使用完后,表大小才会按照MB倍数来增加。
-
页(page)
页是InnoDB存储引擎的最小管理单位,每页大小默认是16KB,从
InnoDB 1.2.x版本开始,可以利用innodb_page_size来改变页size,但是改变只能在初始化InnoDB实例前进行修改,之后便无法进行修改,除非mysqldump导出创建新库,常见的页类型有:数据页、undo页、系统页、事务数据页、插入缓冲位图页、插入缓冲空闲列表页、未压缩的二进制大对象页、压缩的二进制大对象页。 -
行(row)
行对应的是表中的行记录,每页存储最多的行记录也是有硬性规定的最多
16KB/2-200,即7992行(16KB是页大小,我也不明白为什么要这么算,据说是内核定义)
在InnoDB存储引擎中,默认表空间文件是ibdata1,初始化为10M,且可以扩展
mysql(root@localhost:(none):03:16:21)>show variables like 'innodb_data%';
+-----------------------+------------------------+
| Variable_name | Value |
+-----------------------+------------------------+
| innodb_data_file_path | ibdata1:10M:autoextend |
| innodb_data_home_dir | |
+-----------------------+------------------------+
2 rows in set (0.01 sec)
实际上,InnoDB的表空间文件是可以修改的,使用以下语句就可以修改:
Innodb_data_file_path=ibdata1:370M;ibdata2:50M:autoextend
使用共享表空间存储方式时,Innodb的所有数据保存在一个单独的表空间里面,而这个表空间可以由很多个文件组成,一个表可以跨多个文件存在,所以其大小限制不再是文件大小的限制,而是其自身的限制。从Innodb的官方文档中可以看到,其表空间的最大限制为64TB,也就是说,Innodb的单表限制基本上也在64TB左右了,当然这个大小是包括这个表的所有索引等其他相关数据。
而在使用单独表空间存储方式时,每个表的数据以一个单独的文件来存放,这个时候的单表限制,又变成文件系统的大小限制了。
以下即为不同平台下,单独表空间文件最大限度:
| Operating System | 文件系统 | Limit |
|---|---|---|
| Win32 | FAT/FAT32 | 2GB/4GB |
| Win32 | NTFS | 2TB (possibly larger) |
| Linux 2.4+ | (using ext3 file system) | 4TB |
| Solaris 9/10 | 16TB | |
| MacOS X | HFS+ | 2TB |
| NetWare | NSS file system | 8TB |
※以下是MySQL文档中的内容:
Windows用户请注意: FAT和VFAT (FAT32)不适合MySQL的生产使用。应使用NTFS。
2. B树与B+树
B树与B+树通常用于数据库和操作系统的文件系统中。NTFS, ReiserFS, NSS, XFS, JFS, ReFS 和BFS等文件系统都在使用B+树作为元数据索引。B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。
2.1. B树
定义:
B树(B-TREE)满足如下条件,即可称之为m阶B树:
- 每个节点之多拥有m棵子树;
- 根结点至少拥有两颗子树(存在子树的情况下);
- 除了根结点以外,其余每个分支结点至少拥有 m/2 棵子树;
- 所有的叶结点都在同一层上;
- 有 k 棵子树的分支结点则存在 k-1 个关键码,关键码按照递增次序进行排列;
- 关键字数量需要满足ceil(m/2)-1 <= n <= m-1;
2.2. B+树
定义:
B+树满足如下条件,即可称之为m阶B+树:
- 根结点只有一个,分支数量范围为[2,m]
- 分支结点,每个结点包含分支数范围为[ceil(m/2), m];
- 分支结点的关键字数量等于其子分支的数量减一,关键字的数量范围为[ceil(m/2)-1, m-1],关键字顺序递增;
- 所有叶子结点都在同一层;
2.3. B树与B+树区别:
以m阶树为例:
- 关键字不同:B+树中分支结点有m个关键字,其叶子结点也有m个,但是B树虽然也有m个子结点,但是其只拥有m-1个关键字。
- 存储位置不同:B+树非叶子节点的关键字只起到索引作用,实际的关键字存储在叶子节点,B树的非叶子节点也存储关键字。
- 分支构造不同:B+树的分支结点仅仅存储着关键字信息和儿子的指针,也就是说内部结点仅仅包含着索引信息。
- 查询不同(稳定):B树在找到具体的数值以后,则结束,而B+树则需要通过索引找到叶子结点中的数据才结束,也就是说B+树的搜索过程中走了一条从根结点到叶子结点的路径。
3. 聚簇索引和二级索引
3.1. 聚簇索引
每个InnoDB的表都拥有一个索引,称之为聚簇索引,此索引中存储着行记录,一般来说,聚簇索引是根据主键生成的。为了能够获得高性能的查询、插入和其他数据库操作,理解InnoDB聚簇索引是很有必要的。
聚簇索引按照如下规则创建:
- 当定义了主键后,InnoDB会利用主键来生成其聚簇索引;
- 如果没有主键,InnoDB会选择一个非空的唯一索引来创建聚簇索引;
- 如果这也没有,InnoDB会隐式的创建一个自增的列来作为聚簇索引。
Note: 对于选择唯一索引的顺序是按照定义唯一索引的顺序,而非表中列的顺序, 同时选中的唯一索引字段会充当为主键,或者InnoDB隐式创建的自增列也可以看做主键。
聚簇索引整体是一个b+树,非叶子节点存放的是键值,叶子节点存放的是行数据,称之为数据页,这就决定了表中的数据也是聚簇索引中的一部分,数据页之间是通过一个双向链表来链接的,上文说到B+树是一棵平衡查找树,也就是聚簇索引的数据存储是有序的,但是这个是逻辑上的有序,但是在实际在数据的物理存储上是,因为数据页之间是通过双向链表来连接,假如物理存储是顺序的话,那维护聚簇索引的成本非常的高。